Power Of 2 CS 175: Project in AI
Status Report
A mid-project update covering our approach, key design decisions, issues encountered, and what remains ahead.
In this project, we train two different models using two different approaches and compare their performance on the game 2048. Specifically, we implement and evaluate PPO (Proximal Policy Optimization) and DQN (Deep Q-Network), then compare which model advances further — measured by highest tile reached and total score — as well as examining the strengths and weaknesses each approach exhibits in the context of 2048's state space.
A walkthrough video covering our current progress, approach, and preliminary results.
One of the models we are training is a Deep Q-Network (DQN) using a Multilayer Perceptron policy. DQN takes in a 4×4 2D array representing the board state, where 0 represents empty cells and positive integers represent the power of 2 occupying that cell — for example, a cell with value 3 represents 2³ = 8. This encoded array is passed to a hidden MLP network that learns patterns correlated with high rewards, then outputs a discrete action (0–3, corresponding to up, down, left, right) based on the estimated Q-value for each action.
After making the selected move, the transition is stored in a replay buffer. During training, DQN samples randomly from this buffer and checks the resulting board state, receiving rewards for transitions that lead to a higher total score. This decouples the temporal order of experience from learning, reducing correlation between consecutive updates.
where y = r + γ · max_a' Q(s', a'; θ⁻)
The target Q-value y is computed using a separate frozen target network (θ⁻), updated periodically. This stabilizes training by preventing the moving target problem inherent in naive Q-learning, where the network would otherwise be chasing a constantly shifting objective. Gradients are backpropagated through the loss to update the online network θ.
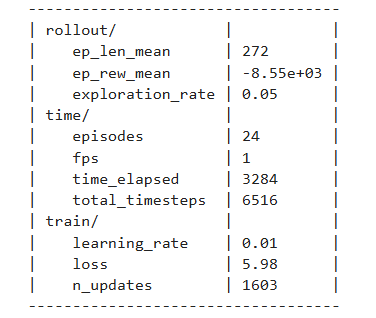
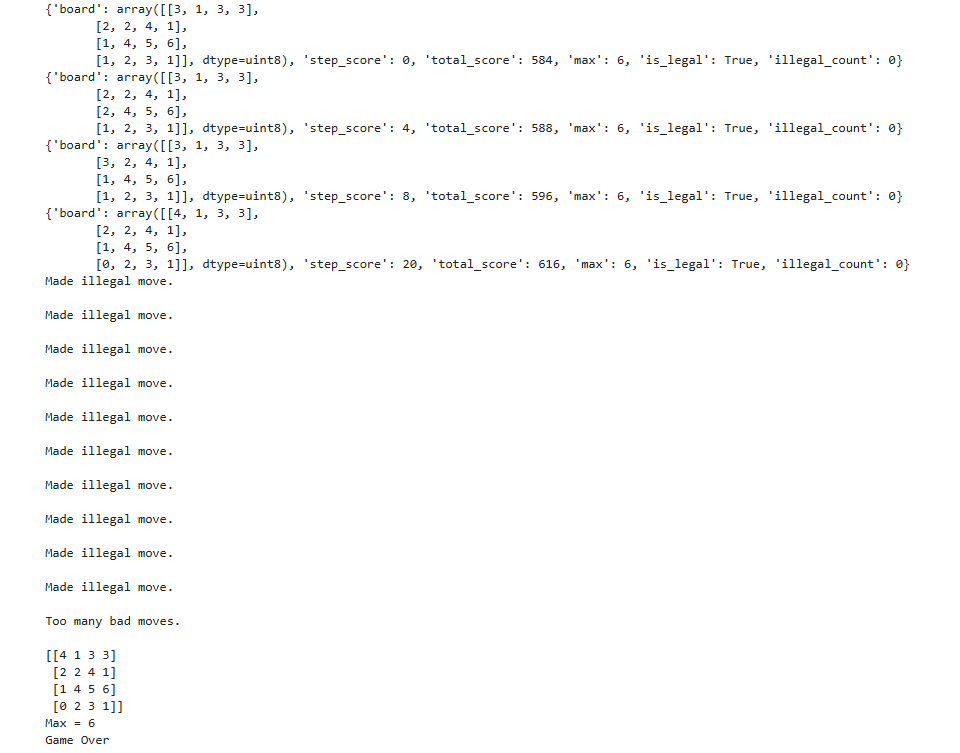
With the default DQN environment, the model does not learn to avoid illegal moves — moves where the board state does not change — and ultimately gets stuck repeating them indefinitely. Penalizing illegal moves was attempted, but the model still lacked persistent memory of why a specific move was illegal for a given board state, causing it to repeat the same mistake. The next step is to mask illegal moves entirely at the action selection stage, preventing them from ever being chosen.
The PPO model uses a fully custom training loop with a CNN + MLP dual-path architecture. Unlike DQN's off-policy Q-value approach, PPO is an on-policy actor-critic method that directly optimizes a clipped surrogate objective, preventing destructively large policy updates while still making meaningful gradient steps each iteration.
The board is first log2-encoded: each tile value t is mapped to log₂(t) / 17, compressing the range 2–131072 into a uniform [0, 1] scale. This encoded board is then processed by two parallel paths:
The convolutional path sees the board spatially as a (1, 4, 4) image, learning positional tile relationships such as corner anchoring and adjacency. The flat MLP path provides global context over all 16 cells simultaneously. Their outputs are concatenated and passed to separate policy and value heads.
The shaped reward for each step combines four components:
The base term log₂(merge_score + 1) is scale-invariant — merging two 512 tiles (score 1024) yields log₂(1025) ≈ 10, while merging two 2 tiles (score 4) yields log₂(5) ≈ 2.3, a proportional difference rather than a 256× raw difference. The monotonicity penalty accumulates log₂ differences across adjacent tile pairs that violate ascending order in any row or column:
Rather than using raw returns or single-step TD errors, advantages are computed via GAE with γ = 0.997 and λ = 0.95. Starting from the last step in the rollout buffer and working backwards:
δᵢ is the one-step TD error. GAE exponentially discounts future TD errors, controlled by λ: λ = 0 reduces to pure TD (low variance, high bias), λ = 1 reduces to full Monte Carlo (high variance, low bias). λ = 0.95 sits close to the Monte Carlo end, capturing long multi-step merge sequences without excessive variance. Advantages are then normalized across the batch: Â ← (Â − mean(Â)) / (std(Â) + ε).
For each mini-batch, the probability ratio between the new and old policy is computed, then clipped to prevent large updates:
The entropy bonus H[π_θ] (coefficient 0.02) discourages premature convergence to a deterministic policy, keeping the agent exploring alternative move sequences throughout training. The value loss is computed separately:
Log2-Encoded Board → CNN + MLP Dual-Path Network
Raw tile values span five orders of magnitude (2–131072), making them poor direct inputs. Log2 encoding compresses this to a uniform 1–17 range, giving spatial convolutions and the flat MLP path equally scaled features to work with.
Reward = log₂(merge_score + 1)
Using raw merge scores as reward creates extremely high-variance signal — merging a 1024 tile gives 500× more reward than merging a 2 tile. Log2 transformation keeps the signal bounded and consistent across all tile magnitudes.
Corner Placement Bonus
The agent receives +0.30 · log₂(max_tile + 1) when the maximum tile occupies any corner. Corner anchoring enables cascading collapses — a sequence of moves that merges multiple descending tiles in one sweep without displacing the highest tile.
Monotonicity Penalty
Penalizes moves that produce non-monotonic tile arrangements by accumulating log₂ differences across all adjacent tile pairs that violate ascending order. Monotonic rows and columns make multi-tile chain merges possible in a single move.
Empty Cell Bonus (+0.10 per cell)
A bonus per empty cell discourages filling the board prematurely. As empty cells decrease, legal moves decrease, accelerating game-over. This term keeps the agent actively seeking merge opportunities rather than spreading tiles.
GAE (γ=0.997, λ=0.95)
High γ (0.997) values future rewards heavily, critical for 2048 where the payoff of a strategic merge may not materialize for dozens of moves. λ=0.95 keeps advantage estimates close to Monte Carlo, capturing long multi-step merge sequences without excessive variance.
Large Rollout Buffer (4096 steps)
4096 steps spans multiple complete games, ensuring each policy update sees diverse board configurations including both early-game open boards and late-game crowded states. This prevents gradient updates from overfitting to one game's trajectory.
Mini-Batch PPO (8 epochs, batch 512)
The 4096-step buffer is shuffled and split into 512-sample mini-batches, updated for 8 epochs per rollout. The ε=0.2 clip limits the probability ratio r(θ) to [0.8, 1.2], preventing any single update from overshooting the policy into a bad region.
Separate Adam Optimizers + Cosine LR
Policy (lr=1e-4) and value (lr=5e-4) networks use independent Adam optimizers — the value network uses a 5× higher rate since it has a cleaner regression target. Cosine annealing with warm restarts (T₀=2M steps) progressively reduces both rates while periodically resetting to escape local minima.
Gradient Clipping (max_norm=0.5)
Applied after each backward pass via torch.nn.utils.clip_grad_norm_. Without clipping, rare high-reward merges (e.g. creating a 1024 tile) produce gradient spikes that can catastrophically overwrite previously learned strategies in a single step.
Two Saved Checkpoints
The latest checkpoint saves every 500 episodes and on every new best tile. The best-average checkpoint saves only when the 100-episode rolling mean improves by more than 1%, preventing frequent overwrites from lucky individual games.
Several non-trivial behavioral issues emerged during training that required targeted interventions:
The agent discovered it could prolong its survival by repeatedly submitting illegal moves (moves that don't change the board state) rather than making a real move that risks triggering game-over. With only one legal move remaining, it would cycle through the three illegal ones indefinitely, achieving artificially high episode lengths without any actual progress.
The environment was modified to strictly filter actions — only moves that result in a board state change are permitted. The action selection layer now masks illegal moves before sampling, forcing the agent to always make a move that advances the game state.
The agent converged on a deterministic ring pattern: LEFT, DOWN, RIGHT, UP, repeating indefinitely. This local optimum generates some merges early on but quickly fills the board without building toward high tiles, ultimately ending in game-over from a full board with no merge opportunities.
The learning rate was increased to give the optimizer enough momentum to escape this local minimum. A higher learning rate causes larger weight updates that are sufficient to disrupt the cyclic attractor in policy space, allowing the agent to explore and discover more productive strategies.
The model learned to construct strictly descending rows as a strategy, which is partially correct — monotonic arrangements are good — but it locked into this pattern too rigidly. It would force descending rows even when doing so violated corner placement, ultimately preventing the highest tile from staying anchored and leading to board fragmentation.
The architecture was upgraded from a flat MLP to a CNN + MLP dual-path network. The convolutional path processes the board spatially, allowing the model to recognize 2D positional relationships (corner anchoring, diagonal arrangements, adjacency for merging) rather than treating all 16 cells as an unordered flat vector.
The two primary evaluation metrics are total score (sum of all merge values across the game, matching standard 2048 scoring) and maximum tile reached. These objectively capture both the quantity of merges and their quality.

Qualitative evaluation will additionally examine emergent behavioral patterns: whether the model pushes high tiles to corners, whether it creates snake or diagonal formations, and how frequently it resorts to suboptimal moves under board pressure. Q-value heatmaps will be used to visualize which board states the agent values most highly.
We are interested in evaluating our trained models against two classical search algorithms that are known to perform well on 2048:
Both algorithms handle delayed rewards by construction — MCTS through rollout depth, Expectimax through explicit lookahead — making them a meaningful comparison point for our RL models, which must learn to handle delayed rewards implicitly through training. Comparing against them would contextualize how close our learned policies come to search-quality play.
DQN training runs currently take 30–60 minutes each, and every hyperparameter adjustment requires a full rerun. As the final submission approaches, exhaustive tuning becomes infeasible within the available time budget. We may need to reduce certain hyperparameters (buffer size, timesteps) to shorten individual runs — but smaller training budgets risk producing undertrained models whose performance may not reflect what a fully scaled run would achieve, complicating fair comparison against PPO.
AI tooling was used in the following capacities: