Power Of 2 CS 175: Project in AI
CS 175 · UC Irvine · AI Project
The Game of 2048,
Taught to Think
A deep reinforcement learning experiment pitting three algorithms against each other — DQN vs MCTS vs PPO — to see which one masters the art of exponential tile merging.
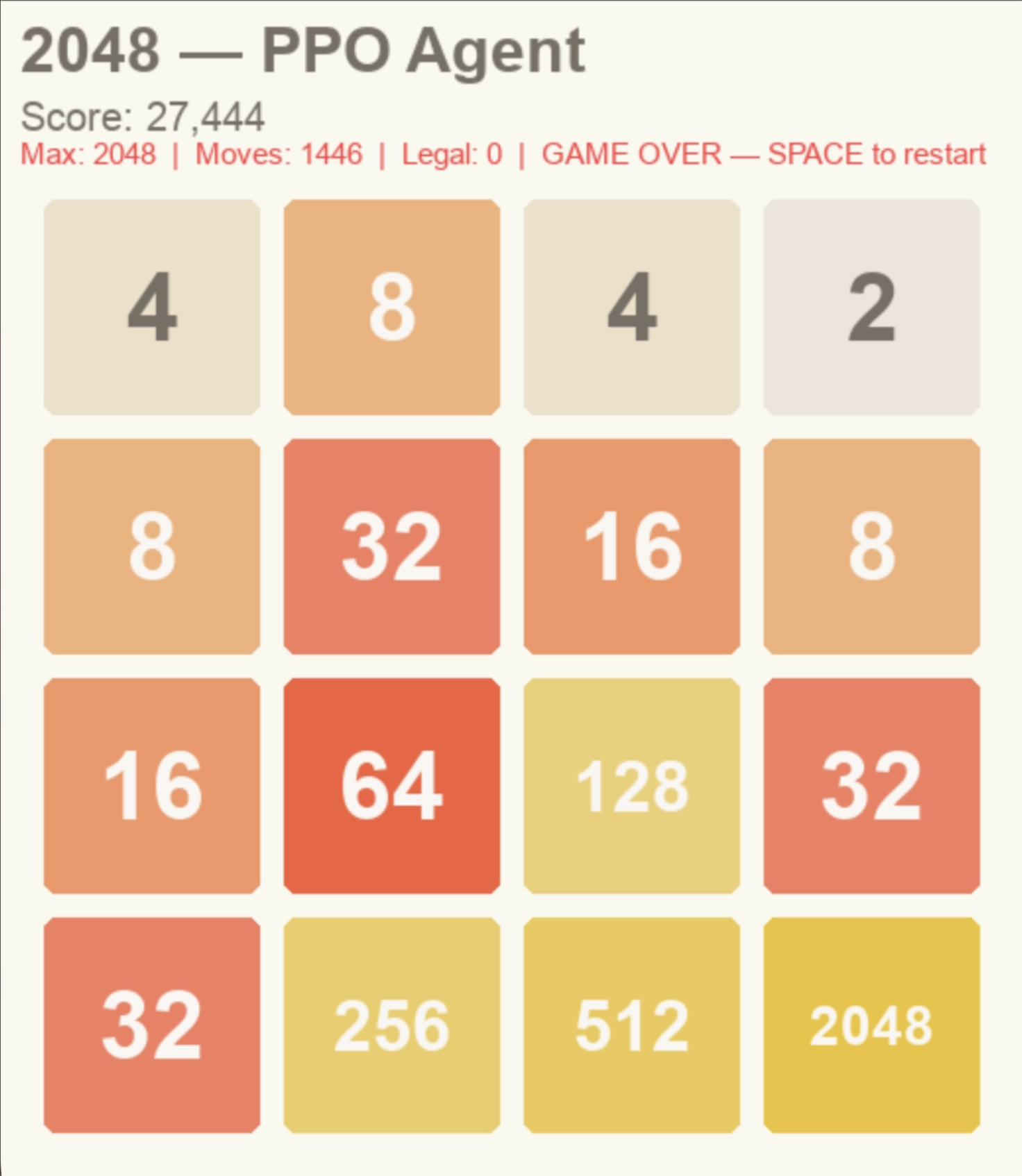
PPO reaches
tile 2048
The Proximal Policy Optimization agent navigates the 4×4 grid through trial and error, learning corner strategies and merge sequences that push tiles to their theoretical maximum.
2048
Best Tile
MCTS
& PPO Algorithm
& PPO Algorithm
3
Models