Power Of 2 CS 175: Project in AI
Final Report
A comprehensive overview of our approach, models, results, and insights from training agents to play 2048.
A final walkthrough video covering our complete approach, all three models, results, and takeaways.


2048 is a solo player web game where the objective is to merge like tiles to eventually — hopefully — produce the 2048 tile. Each tile is a power of 2, and the player begins with twos and fours scattered across the board.

There are 4 possible moves a player can make on any given turn: up, down, left, right. After each move, the game adds a random tile (2 or 4) into a random empty cell. Each move slides all existing tiles in the chosen direction. Only when two like tiles — tiles of the same power of two — collide can they merge into one new tile of the next power of two; the two merged tiles disappear and are replaced by their combined value.
In the beginning of our project, we were only able to just barely get 1024 as the maximum tile. Most of our models were reaching 512.
Presently, we have reached our goal of 2048 using two models — MCTS and PPO (CNN + MLP). All three of our models now consistently reach 1024.
Our goal going forward is to reach 4096 (one power above 2048) and to have all three models, including DQN, reach 2048. We can also explore imitation learning or longer training runs on existing models.
Our motivation for selecting this topic was that everyone on our team already knows how to play 2048. We believed the game had a straightforward success state, and that the action space could be simplified since there are only four possible moves. Lastly, we felt our own gameplay experience and general knowledge of the game allowed us to design better heuristics for reward shaping.
In hindsight, we made some blunders in reward shaping early on — but after additional trials and iteration those were resolved successfully.
The core challenge we found interesting is that 2048 is an inherently random game, making it difficult to learn — especially without heuristics to guide model decision making.
2048 rewards delayed actions combined with a non-linear state space due to the collapsing of tiles column- and row-wise. Rewarding small movements instead of long-term gains causes tiles to be combined without any strict strategy, leading to small noisy movements that produce game-overs. Tile generation is also random — new tiles can appear anywhere on the board as either 2 or 4 — which means RL algorithms cannot rely on strictly deterministic patterns and must develop probabilistic strategies instead.
The real goal is making long-term decisions that increase the mergeability of tiles, extending the reward horizon rather than chasing greedy local score increases. Humans make this same mistake when playing naively. We want models that can exploit strategies leading to good games despite an environment of randomness, non-linear state transitions, and long reward horizons.
One of the models we trained is a Deep Q-Network (DQN) using a Multilayer Perceptron policy. DQN takes in a 4×4 2D array representing the board state, where 0 represents empty cells and positive integers represent the power of 2 occupying that cell — for example, a cell with value 3 represents 2³ = 8. This encoded array is passed to a hidden MLP network that learns patterns correlated with high rewards, then outputs a discrete action (0–3, corresponding to up, down, left, right) based on the estimated Q-value for each action.
After making the selected move, the transition is stored in a replay buffer. During training, DQN samples randomly from this buffer and checks the resulting board state, receiving rewards for transitions that lead to a higher total score. This decouples the temporal order of experience from learning, reducing correlation between consecutive updates.
The target Q-value y is computed using a separate frozen target network (θ⁻), updated periodically. This stabilizes training by preventing the moving target problem inherent in naive Q-learning, where the network would otherwise chase a constantly shifting objective. Gradients are backpropagated through the loss to update the online network θ. This separate target network is why the loss function can appear unstable during training.
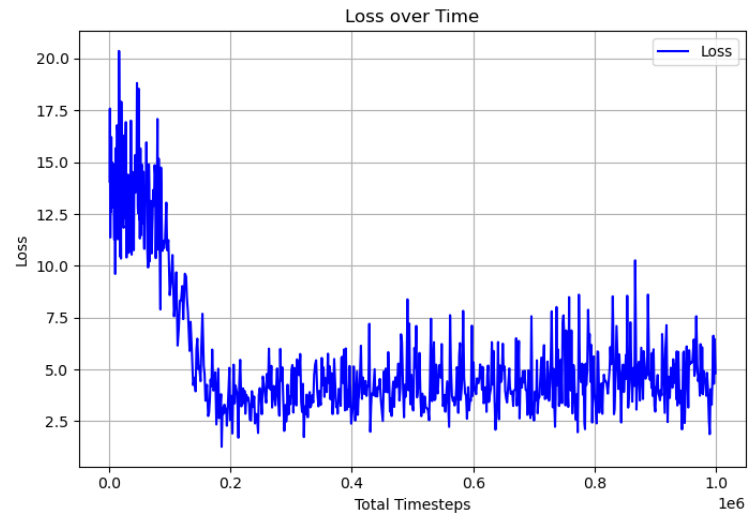
DQN Loss Curve
With the default DQN environment provided by stable_baselines3, the model does not learn to avoid illegal moves — moves where the board state does not change — and ultimately gets stuck repeating them indefinitely. Penalizing illegal moves was attempted, but the model still lacked persistent memory of why a specific move was illegal for a given board state. In the end, we wrapped the environment to train with an illegal move punishment and a corner reward, implementing the corner strategy.
Hyperparameters were not fully fine-tuned due to time constraints. On the hpc3 server without sbatch, training took much longer — sometimes hours — for performance ending in a maximum tile of 64. On the openlab server, training was substantially faster. With larger timesteps, buffer sizes, and batch sizes, training could result in maximum tiles of 100+, though it never reached 1000+. The final DQN implementation shows signs of successfully training with the corner strategy, but reward plateaus prevent it from reaching higher tiles.
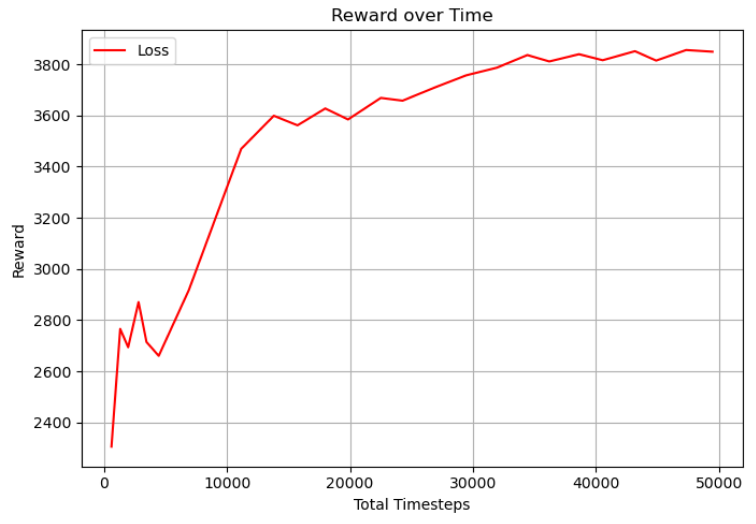
DQN Reward Curve
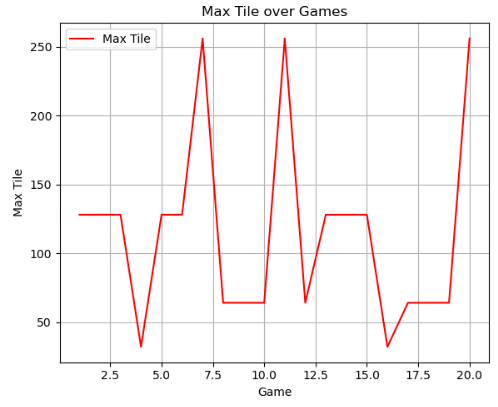
DQN Max Tile Over Training
In the future, we would want to increase or eliminate this reward plateau so the model can learn to reach higher maximum tiles. This could involve implementing more strategies, adjusting the exploration fraction to better account for 2048's inherent randomness, or using a stronger network architecture with additional layers and larger batch sizes.
Another algorithm we implemented is a heuristic-guided Monte Carlo Tree Search (MCTS) that performs n rollouts per move. Unlike PPO and DQN, MCTS does not learn a policy or a value function — it relies entirely on the tree built during search, aggregating rollout results to select moves at each decision point.
At each decision point, MCTS expands nodes for different board states and performs rollouts. While traditional MCTS follows fully random rollouts, this naive approach does not account for two key issues: 2048's inherent randomness and its rapidly changing state space. Results from each rollout are backpropagated up through the tree to update node values, allowing the algorithm to estimate which action will yield the best outcome based on the Upper Confidence Bounds (UCB) formula:
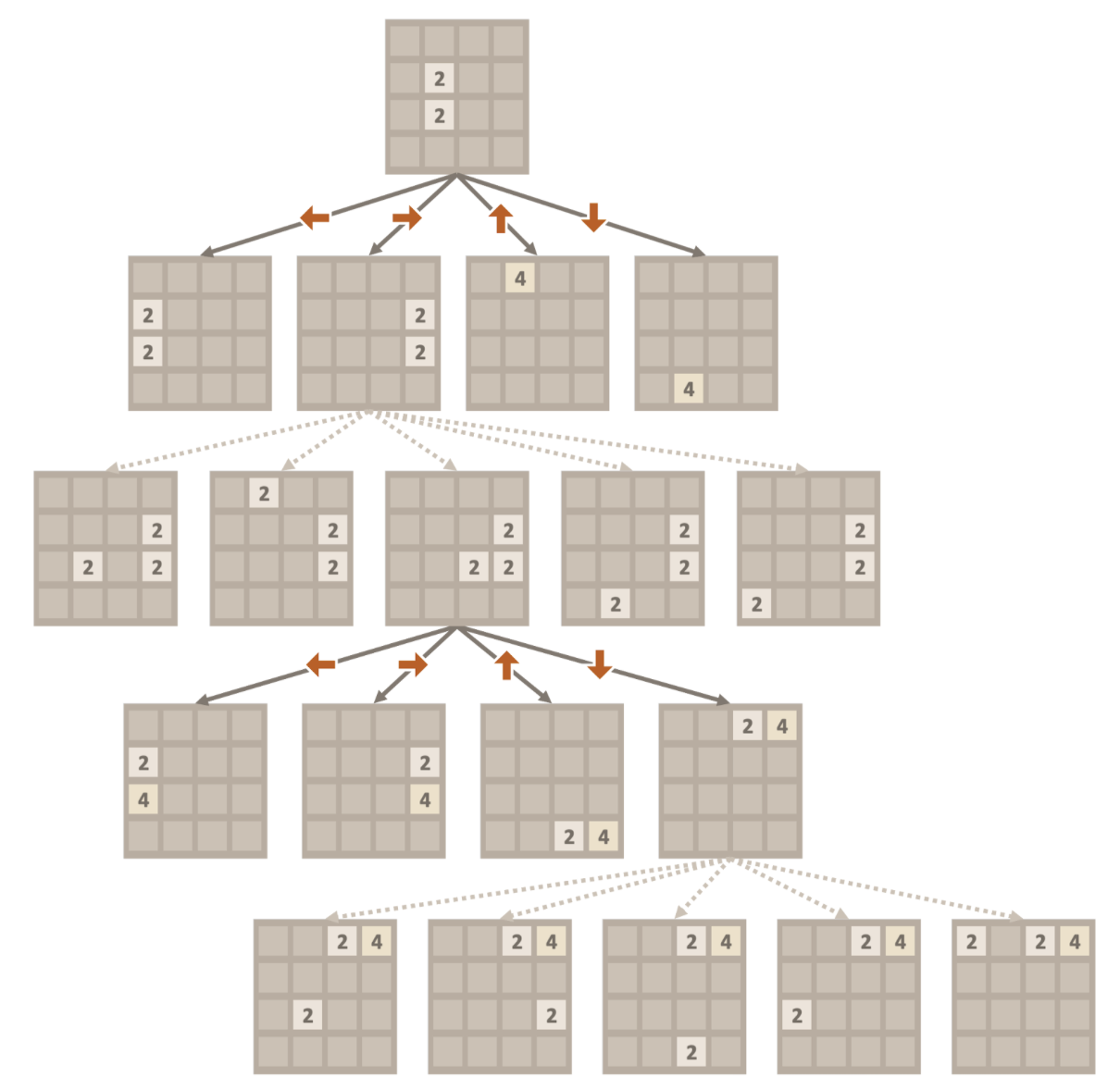
Graphic via poomstas/2048_MCTS @ github
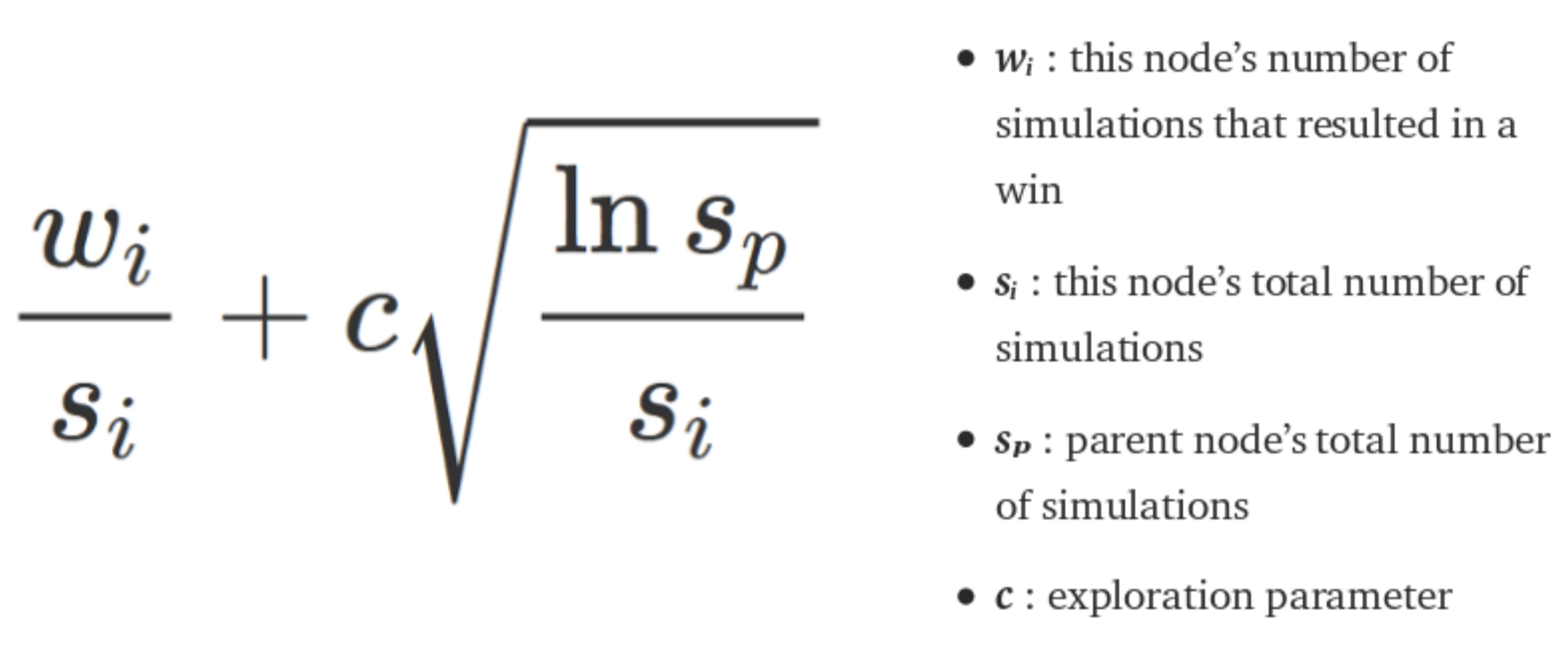
Graphic via StackOverflow
Random rollouts introduce significant noise — especially in a stochastic state space. We added heuristics to guide rollout selection so they follow strategies grounded in real 2048 gameplay:
Empty Tile Weighting
Boards with more empty cells are rewarded. Any move can spawn an unmergeable tile anywhere on the board, so maintaining flexibility by keeping cells open increases future merge opportunities.
Monotonicity Score
Tiles are rewarded for following a snake-like ordering — consistently increasing or decreasing across rows and columns — enabling strategic chaining of merges in a single sweep.
Corner Bias
High-value tiles positioned in a corner receive a bonus. Corner anchoring enables cascading collapses by keeping the highest tile stationary while merging descending tiles around it.
Smoothness
Adjacent tiles with similar values are rewarded because they can be merged given the right opportunity. Smooth boards reduce the number of moves needed to collapse adjacent tiles.
Exploration Constant c
Controls the balance between exploitation of high-value nodes and exploration of less-visited ones in the UCB formula. Tuned experimentally against the other heuristic weights.
Based on these heuristics, we could then do experimental analysis to find the best combination of parameters:
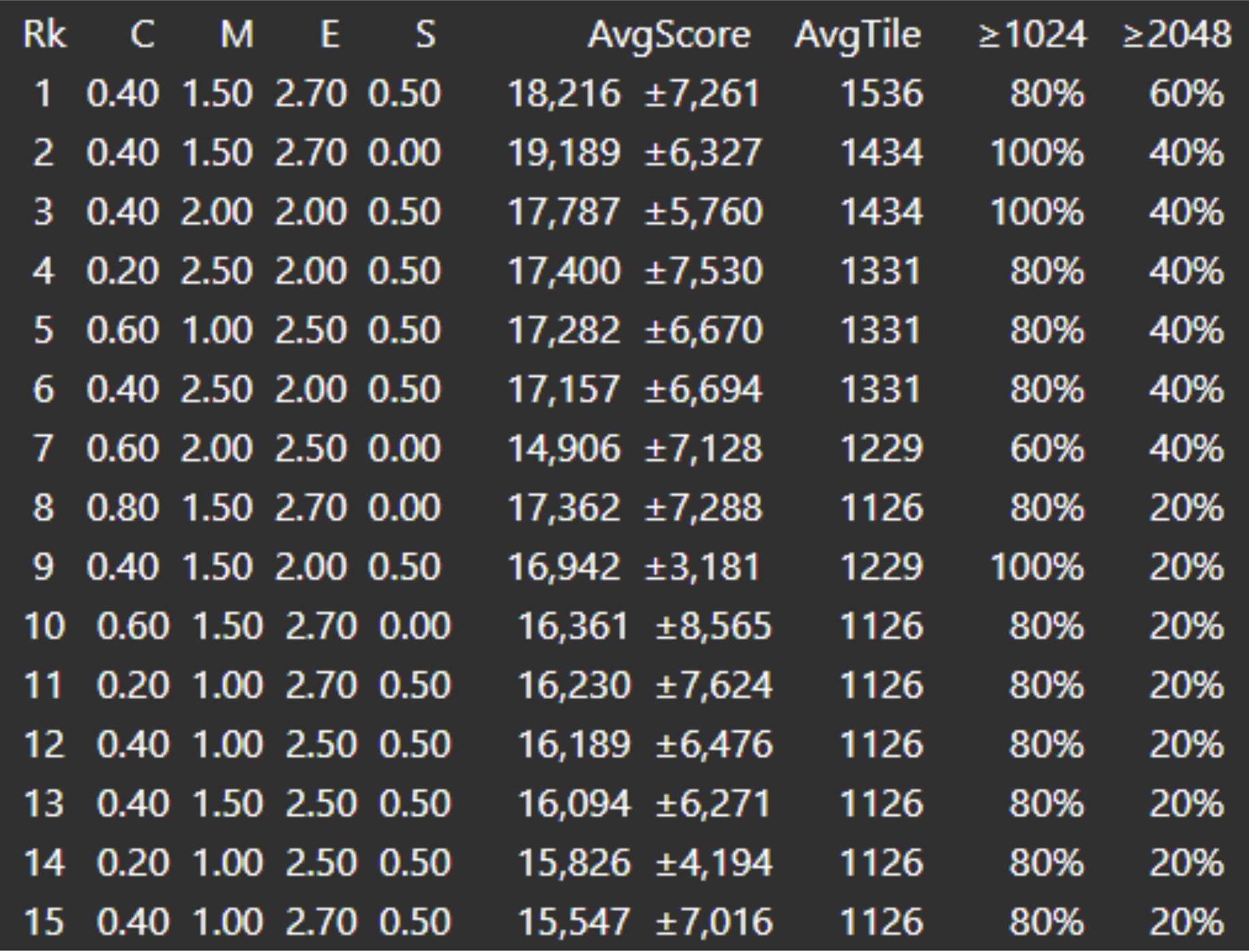
Three rollout parameters were tuned to balance performance against computational cost:
This ultimately results in the best combination of parameters which came out to be:

More rollouts and deeper rollout depth generally produce higher scores by giving the tree more information — but this directly increases time per game. Games that ran faster (less compute) scored lower because they reached game-over sooner, while slower games running around 8 minutes were able to reach the 2048 tile.
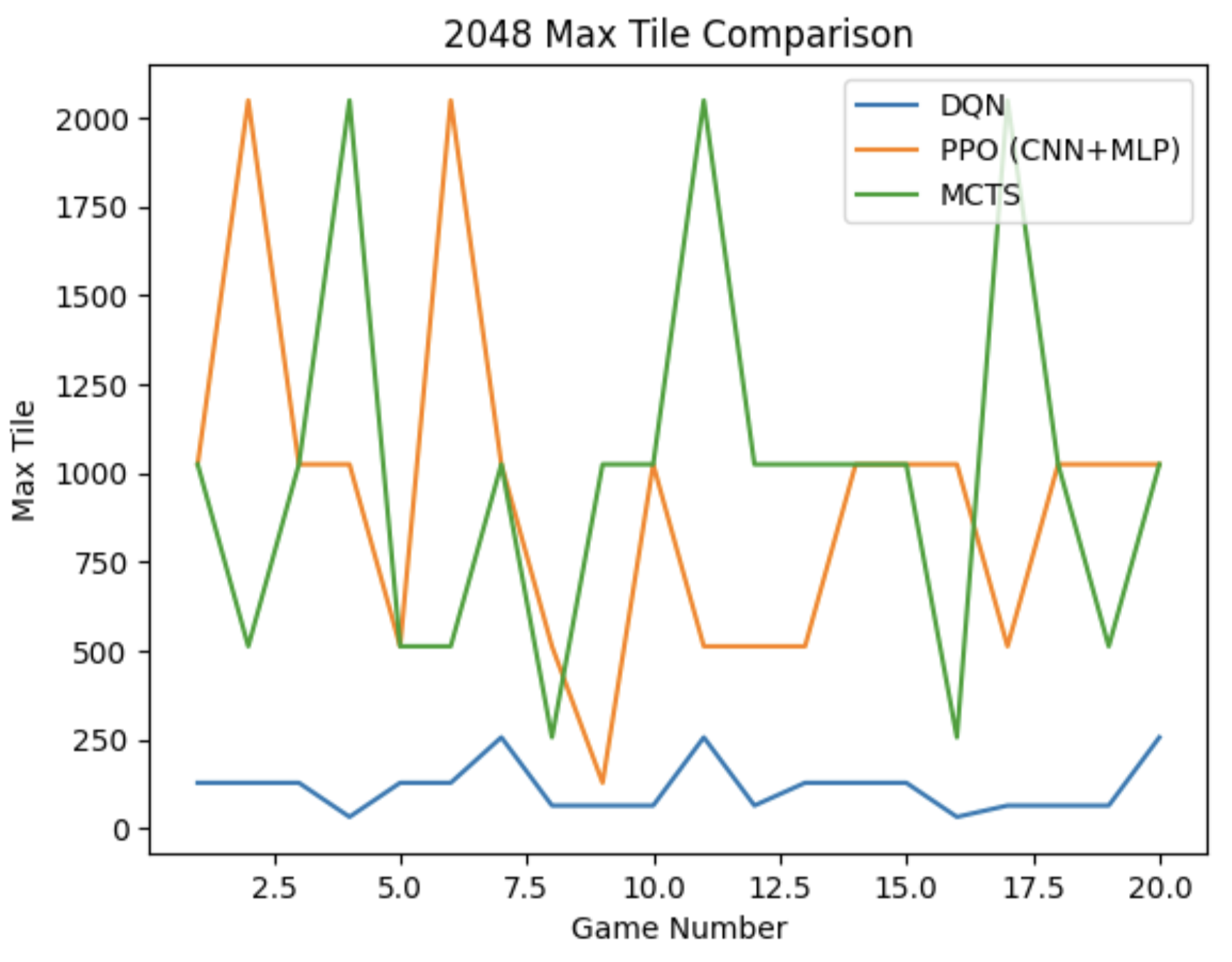
When ran on our baseline of 20 games, we saw:
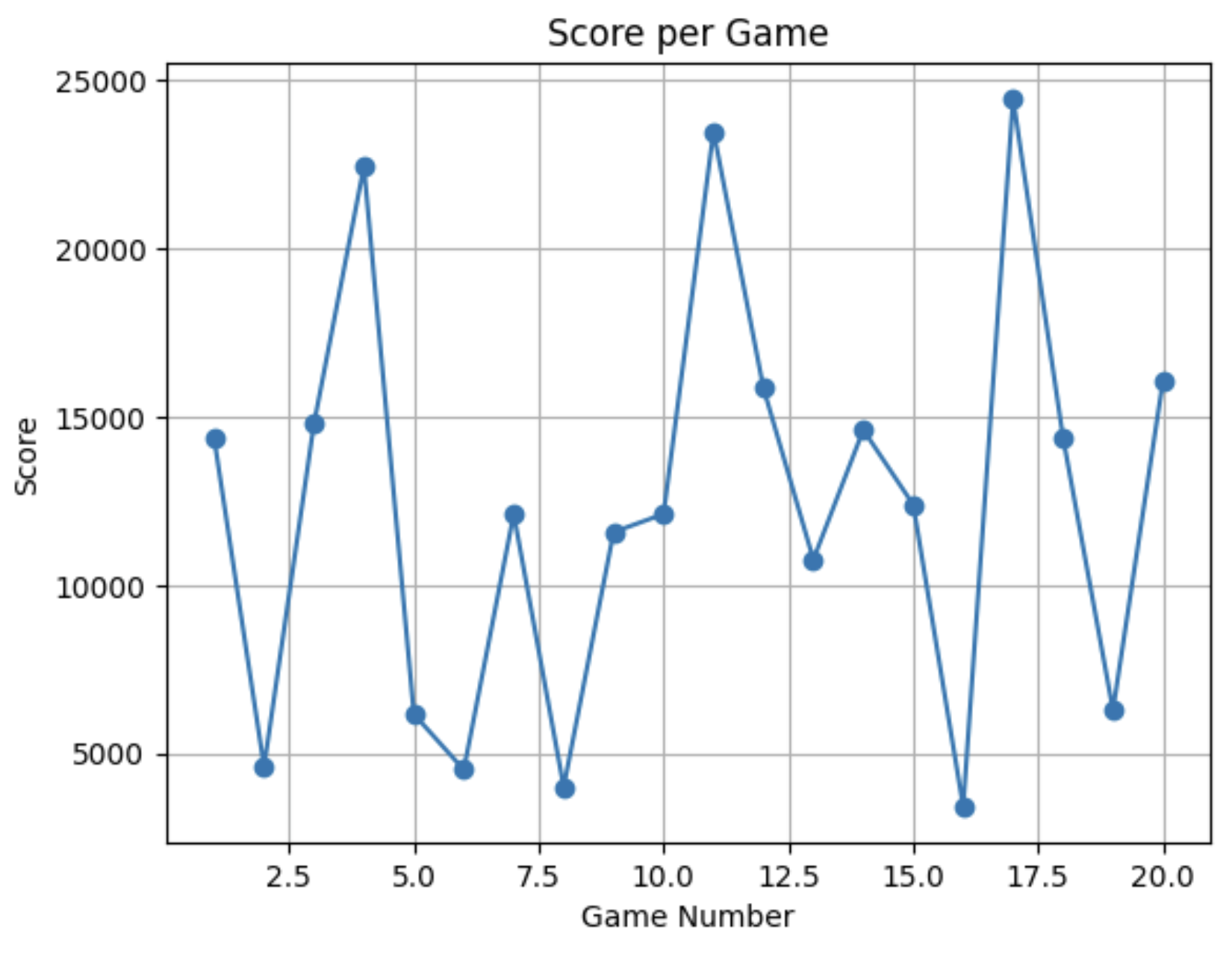
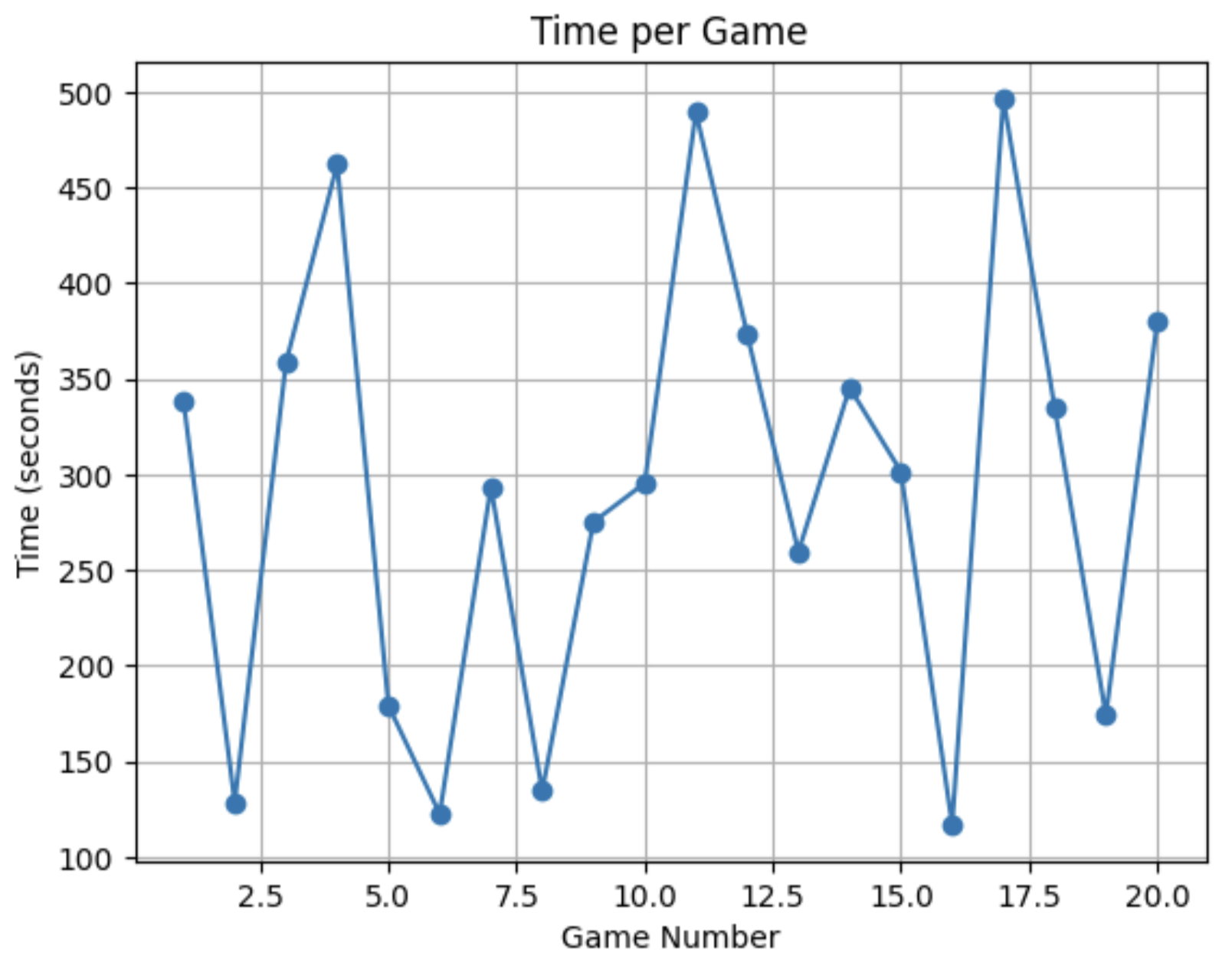
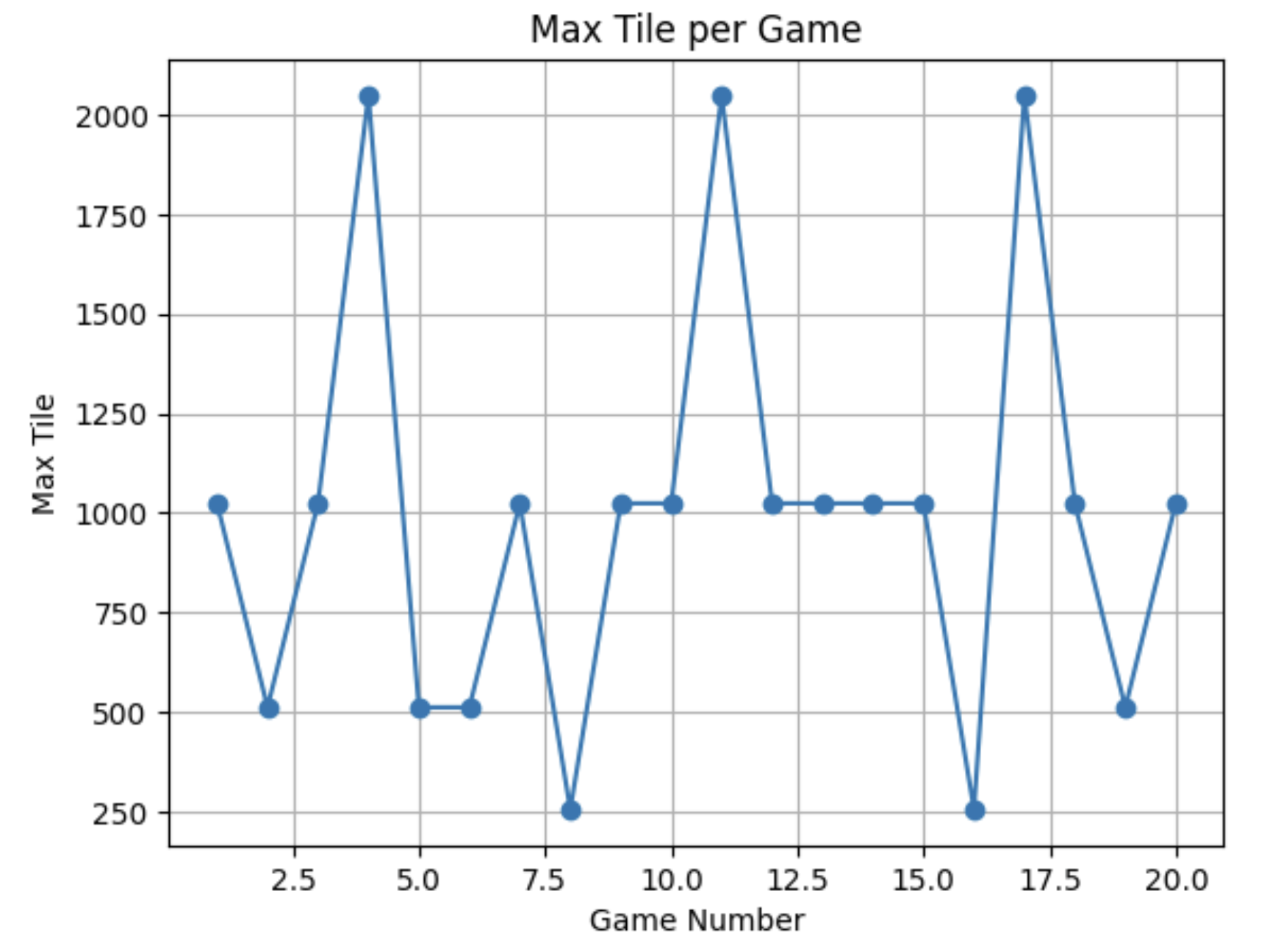

MCTS performance is directly tied to hardware speed. Machines with faster CPUs can run more simulations within the same time budget, producing stronger play. This means identical configurations yield different results across machines — beyond 2048's inherent randomness — and time-based limits are hardware-dependent. MCTS does not retain knowledge between games, making it much more expensive and less scalable than trained models. While it can perform comparably to a tuned RL model given sufficient compute, the runtime cost is substantially higher.
The PPO model uses a fully custom training loop with a CNN + MLP dual-path architecture. Unlike DQN's off-policy Q-value approach, PPO is an on-policy actor-critic method that directly optimizes a clipped surrogate objective, preventing destructively large policy updates while still making meaningful gradient steps each iteration.
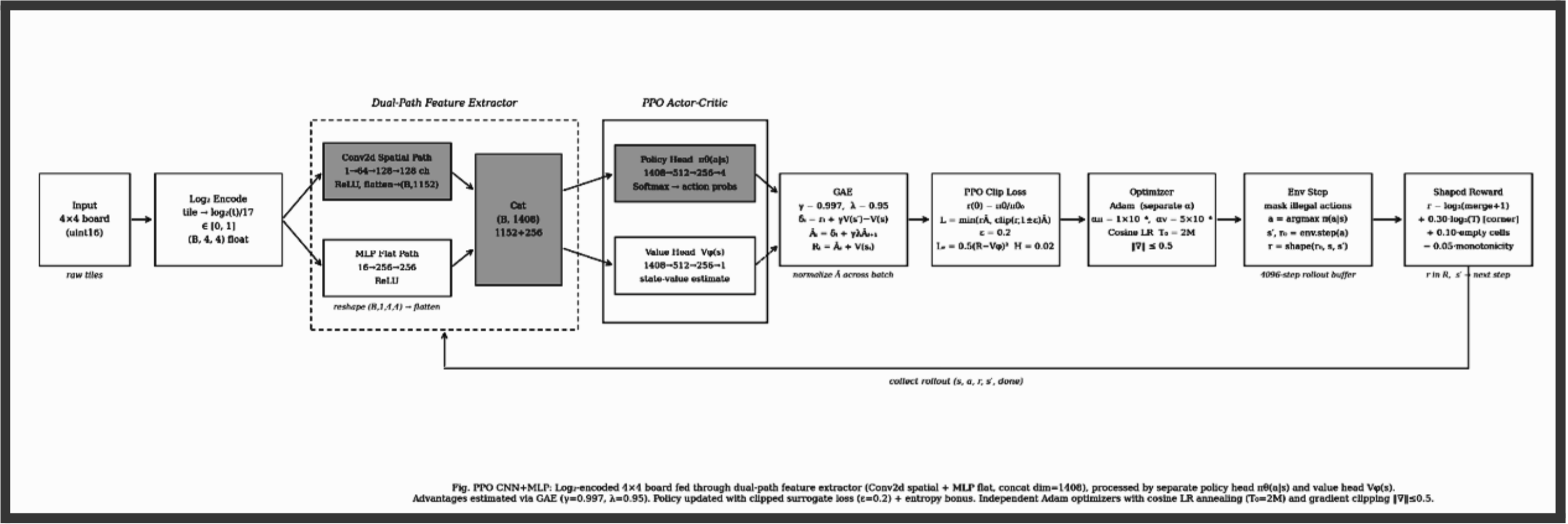
The board is first log₂-encoded: each tile value t is mapped to log₂(t) / 17, compressing the range 2–131072 into a uniform [0, 1] scale. Raw tile values span five orders of magnitude, making them poor direct inputs. Log₂ encoding gives both the convolutional and flat MLP paths equally scaled features to work with.
The encoded board is processed by two parallel paths:
The convolutional path sees the board spatially as a (1, 4, 4) image, learning positional tile relationships: corner anchoring, adjacency for merging, diagonal arrangements. The flat MLP path treats the board as a vector of 16 numbers — every cell talks to every other equally, regardless of position — providing global context over tile distribution. Their outputs are concatenated and passed to separate policy and value heads.
PPO is an actor-critic framework. The actor is the policy π(a|s) that looks at the current board state and decides which of the four actions to take. The critic is the value function V(s) — it looks at the board and produces a score quantifying how good the current state actually is. The critic never takes actions; it only judges the actor.
A critical problem in policy gradient methods is that overly aggressive updates can erase all previously learned strategies. PPO counters this using the ratio between the new and old policy:
The entropy bonus H[π_θ] (coefficient 0.02) discourages premature convergence to a deterministic policy, keeping the agent exploring alternative move sequences throughout training. The value loss is computed separately:
Rather than using raw returns or single-step TD errors, advantages are computed via GAE with γ = 0.997 and λ = 0.95. Starting from the last step in the rollout buffer and working backwards:
δᵢ is the one-step TD error. GAE exponentially discounts future TD errors, controlled by λ: λ = 0 reduces to pure TD (low variance, high bias), λ = 1 reduces to full Monte Carlo (high variance, low bias). λ = 0.95 sits close to the Monte Carlo end, capturing long multi-step merge sequences without excessive variance. Advantages are then normalized across the batch: Â ← (Â − mean(Â)) / (std(Â) + ε).
The actor and critic use independent Adam optimizers with separate learning rates. Adam provides two key improvements over basic gradient descent:
Momentum: instead of using only the current gradient, Adam maintains a running average of past gradients, smoothing noisy updates. If the model has historically pointed in a given direction, it takes a larger step that way. Adaptive learning rates: each parameter receives its own effective learning rate — parameters with consistently large gradients are scaled down, small gradients are scaled up. The m/√v term is what makes learning adaptive.
Using separate optimizers means the critic (value_lr = 5e-4) and actor (policy_lr = 1e-4) can move at different speeds. In practice, the critic converges earlier, supplying better advantage signals to the actor sooner — our model reached 2048 at around 50k episodes.
The shaped reward for each step combines four components:
The base term log₂(merge_score + 1) is scale-invariant — merging two 512 tiles (score 1024) yields log₂(1025) ≈ 10, while merging two 2 tiles (score 4) yields log₂(5) ≈ 2.3, a proportional difference rather than a 256× raw difference. The monotonicity penalty accumulates log₂ differences across adjacent tile pairs that violate ascending order in any row or column:
Log₂-Encoded Board → CNN + MLP Dual-Path Network
Raw tile values span five orders of magnitude (2–131072), making them poor direct inputs. Log₂ encoding compresses this to a uniform 1–17 range, giving both paths equally scaled features to work with.
Reward = log₂(merge_score + 1)
Using raw merge scores creates extremely high-variance signal — merging a 1024 tile gives 500× more reward than merging a 2 tile. Log₂ transformation keeps the signal bounded and consistent across all tile magnitudes.
Corner Placement Bonus
The agent receives +0.30 · log₂(max_tile + 1) when the maximum tile occupies any corner. Corner anchoring enables cascading collapses — a sequence of moves that merges multiple descending tiles in one sweep without displacing the highest tile.
Monotonicity Penalty
Penalizes moves that produce non-monotonic tile arrangements by accumulating log₂ differences across all adjacent pairs that violate ascending order. Monotonic rows and columns make multi-tile chain merges possible in a single move.
Empty Cell Bonus (+0.10 per cell)
A bonus per empty cell discourages filling the board prematurely. As empty cells decrease, legal moves decrease, accelerating game-over. This term keeps the agent seeking merge opportunities rather than spreading tiles.
GAE (γ=0.997, λ=0.95)
High γ (0.997) values future rewards heavily — critical for 2048 where the payoff of a strategic merge may not materialize for dozens of moves. λ=0.95 keeps advantage estimates close to Monte Carlo, capturing long multi-step merge sequences without excessive variance.
Large Rollout Buffer (4096 steps)
4096 steps spans multiple complete games, ensuring each policy update sees diverse board configurations — both early-game open boards and late-game crowded states. This prevents gradient updates from overfitting to any single game trajectory.
Mini-Batch PPO (8 epochs, batch 512)
The 4096-step buffer is shuffled and split into 512-sample mini-batches, updated for 8 epochs per rollout. The ε=0.2 clip limits the probability ratio r(θ) to [0.8, 1.2], preventing any single update from overshooting into a bad policy region.
Separate Adam Optimizers + Cosine LR
Policy (lr=1e-4) and value (lr=5e-4) networks use independent Adam optimizers. Cosine annealing with warm restarts (T₀=2M steps) progressively reduces both rates while periodically resetting to escape local minima.
Gradient Clipping (max_norm=0.5)
Applied after each backward pass via torch.nn.utils.clip_grad_norm_. Without clipping, rare high-reward merges produce gradient spikes that can catastrophically overwrite previously learned strategies in a single step.
Two Saved Checkpoints
The latest checkpoint saves every 500 episodes and on every new best tile. The best-average checkpoint saves only when the 100-episode rolling mean improves by more than 1%, preventing frequent overwrites from lucky individual games.
In the beginning, the model never made any valid moves. With the GUI it was immediately obvious because the board would never change even as the move counter incremented.
The environment was modified to strictly filter actions — only moves that result in a board state change are permitted. The action selection layer masks illegal moves before sampling.
Using imitation training in early iterations, the model converged on a deterministic ring pattern: LEFT, DOWN, RIGHT, UP, repeating until the board was full.
The learning rate was increased to give the optimizer enough momentum to escape this local minimum, and the CNN + MLP dual-path architecture replaced the flat MLP, enabling spatial awareness that disrupted the cyclic attractor.
Mergeable tiles were unable to merge because their positions were diagonally opposite. With only a flat MLP there was no spatial awareness to recognize and resolve diagonal separation.
Adding the empty tiles heuristic combined with introducing the MLP path alongside the CNN resolved this. Training had to restart from scratch.
One reward for high tiles in general was made too lucrative. The actor went on a merging spree and produced many "holes" — isolated low-power tiles trapped among high tiles — breaking monotonicity and fragmenting the board.
The reward coefficient was reduced and replaced with the more targeted corner placement bonus, which rewards high tiles only when they occupy a corner rather than anywhere on the board.
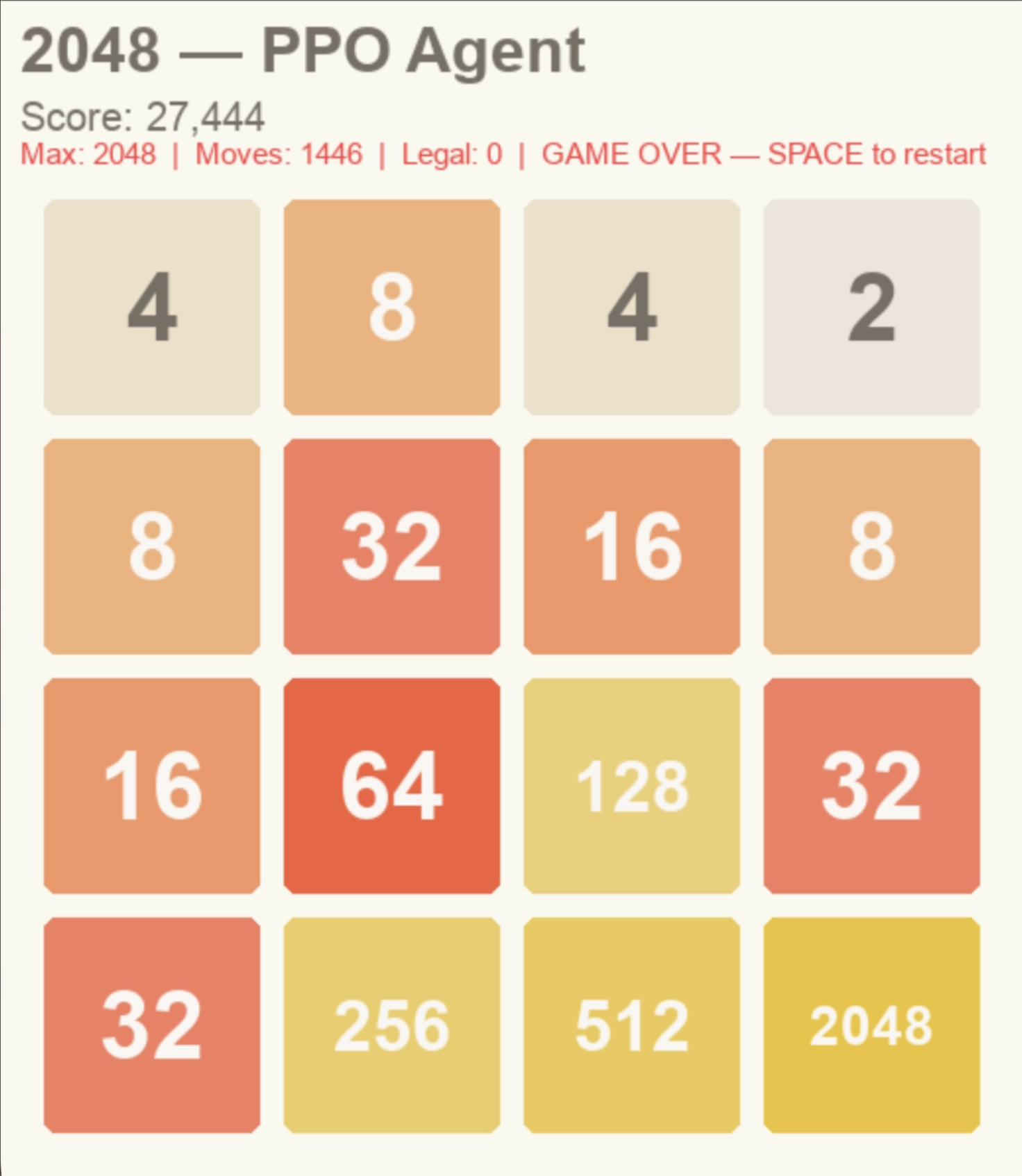
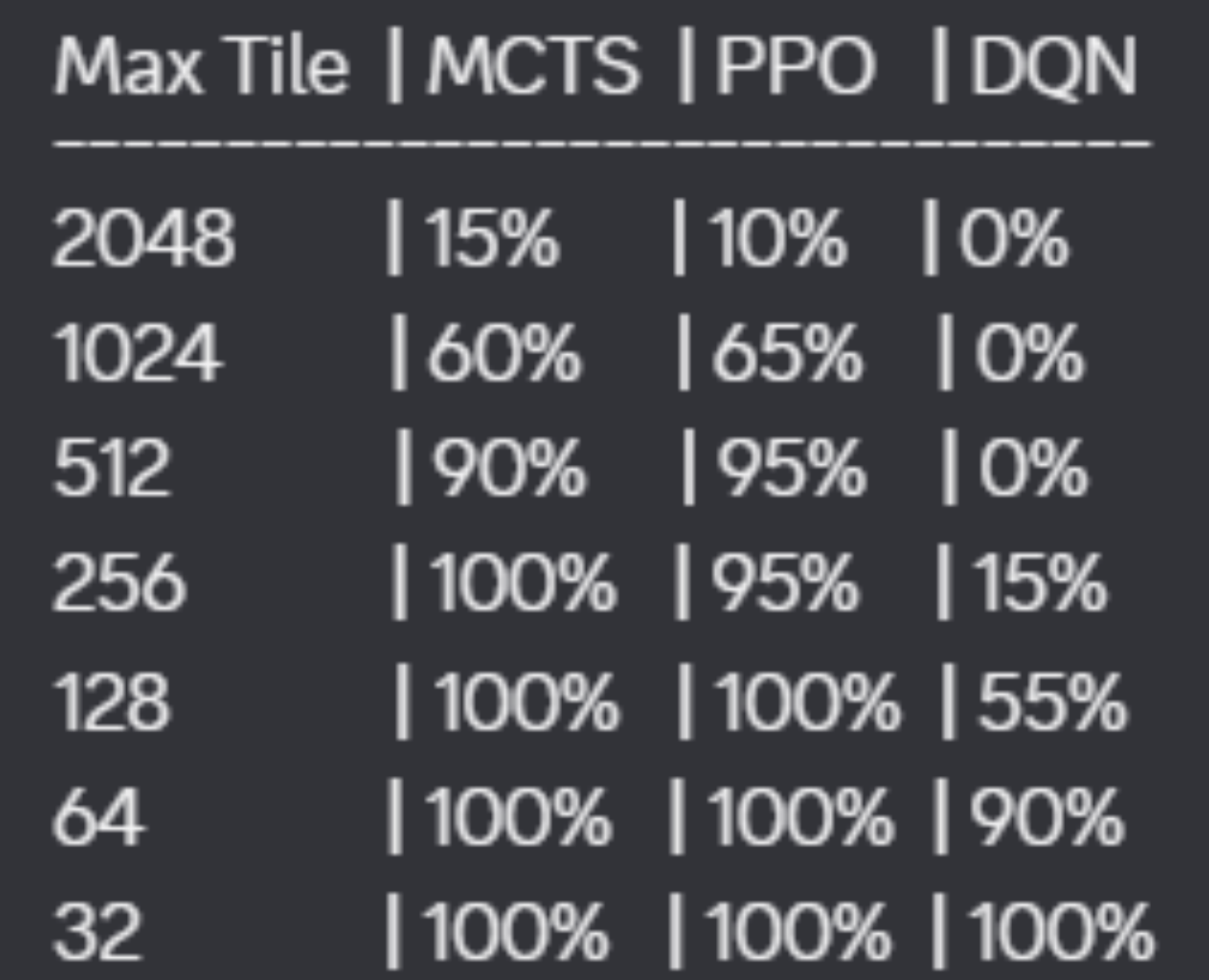
10% of results from a 20-game test end with a max tile of 2048. The average max tile across all 20 games is 1024, and the lowest max tile recorded is 512. Average time per game is approximately 1.5 seconds — at maximum, 3 seconds. This model was trained to approximately 23 million steps. Total testing time for all 20 games is under 30 seconds.
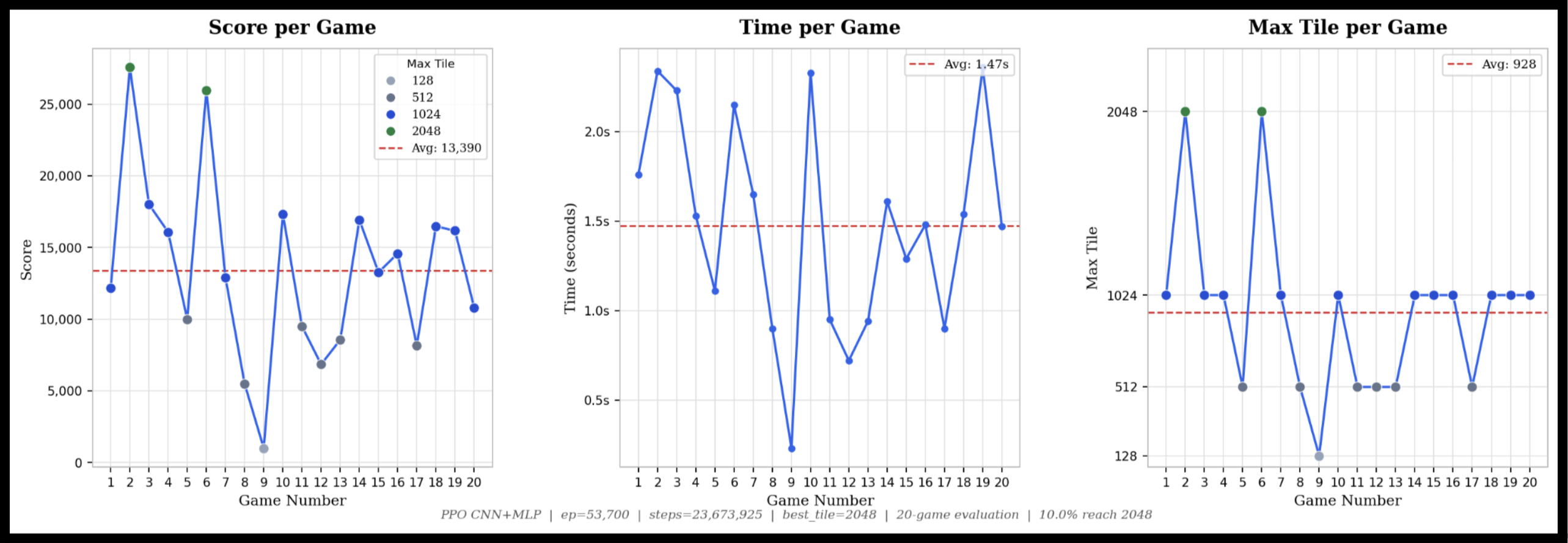
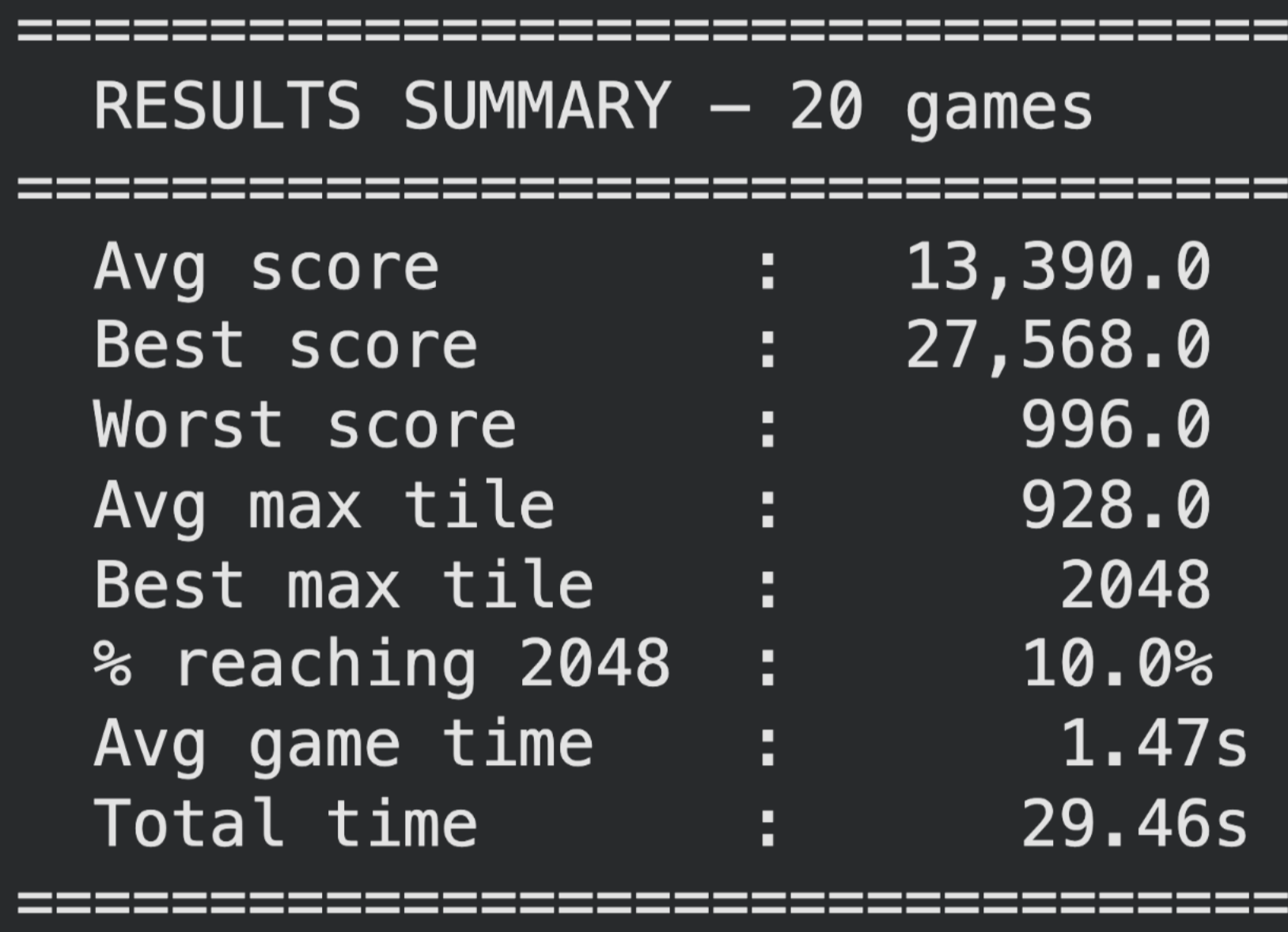
The two primary evaluation metrics are total score (sum of all merge values across the game, matching standard 2048 scoring) and maximum tile reached. These objectively capture both the quantity of merges and their quality.
| Model | 2048 Rate | Avg Max Tile | Avg Time / Game | Learns Between Games |
|---|---|---|---|---|
| PPO (CNN + MLP) | 10% (20-game test) | 1024 | ~1.5s | Yes — trained weights |
| MCTS (heuristic) | Reaches 2048 w/ sufficient compute | Variable by hardware | Minutes per game | No — search from scratch |
| DQN (MLP) | Not yet | ~64–100+ | Fast | Yes — trained weights |
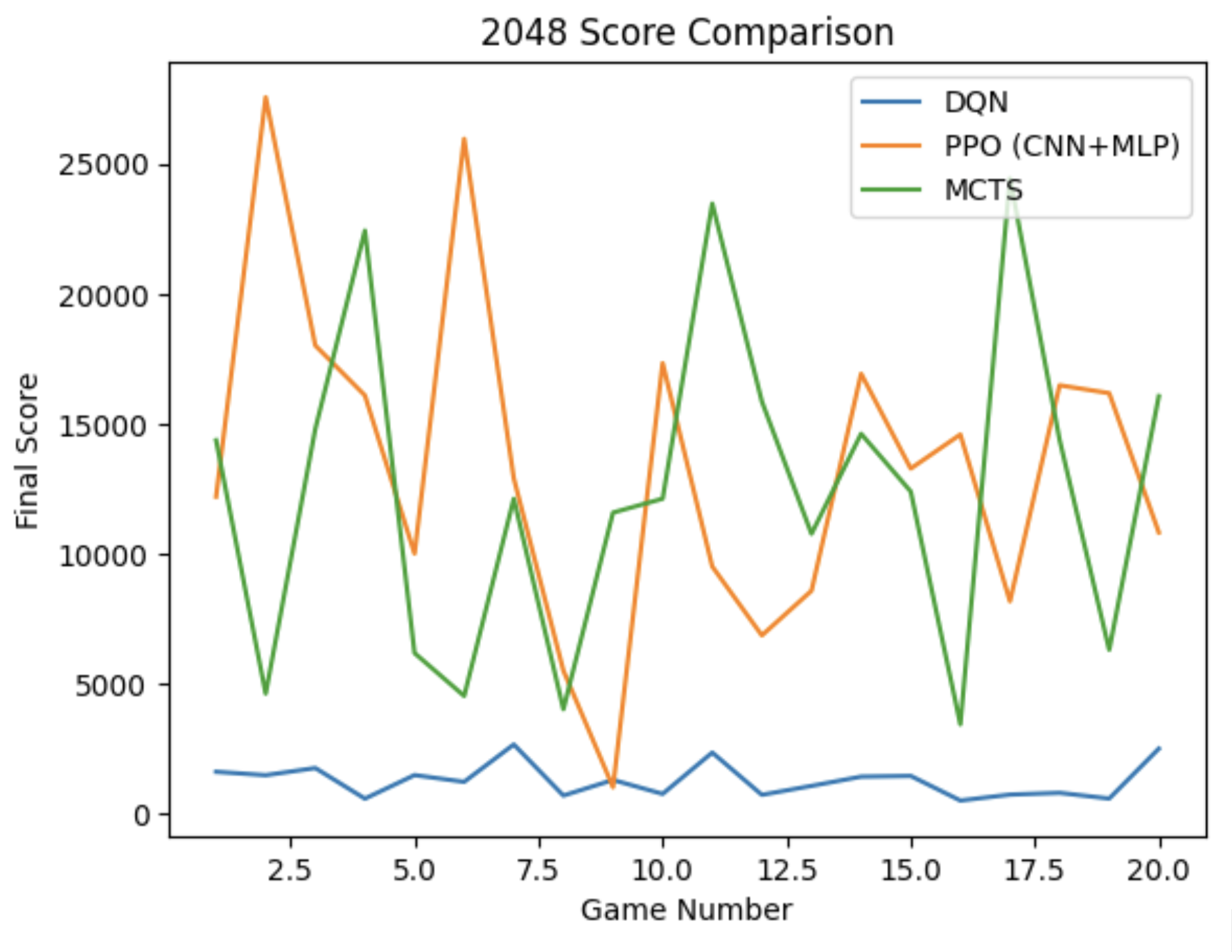
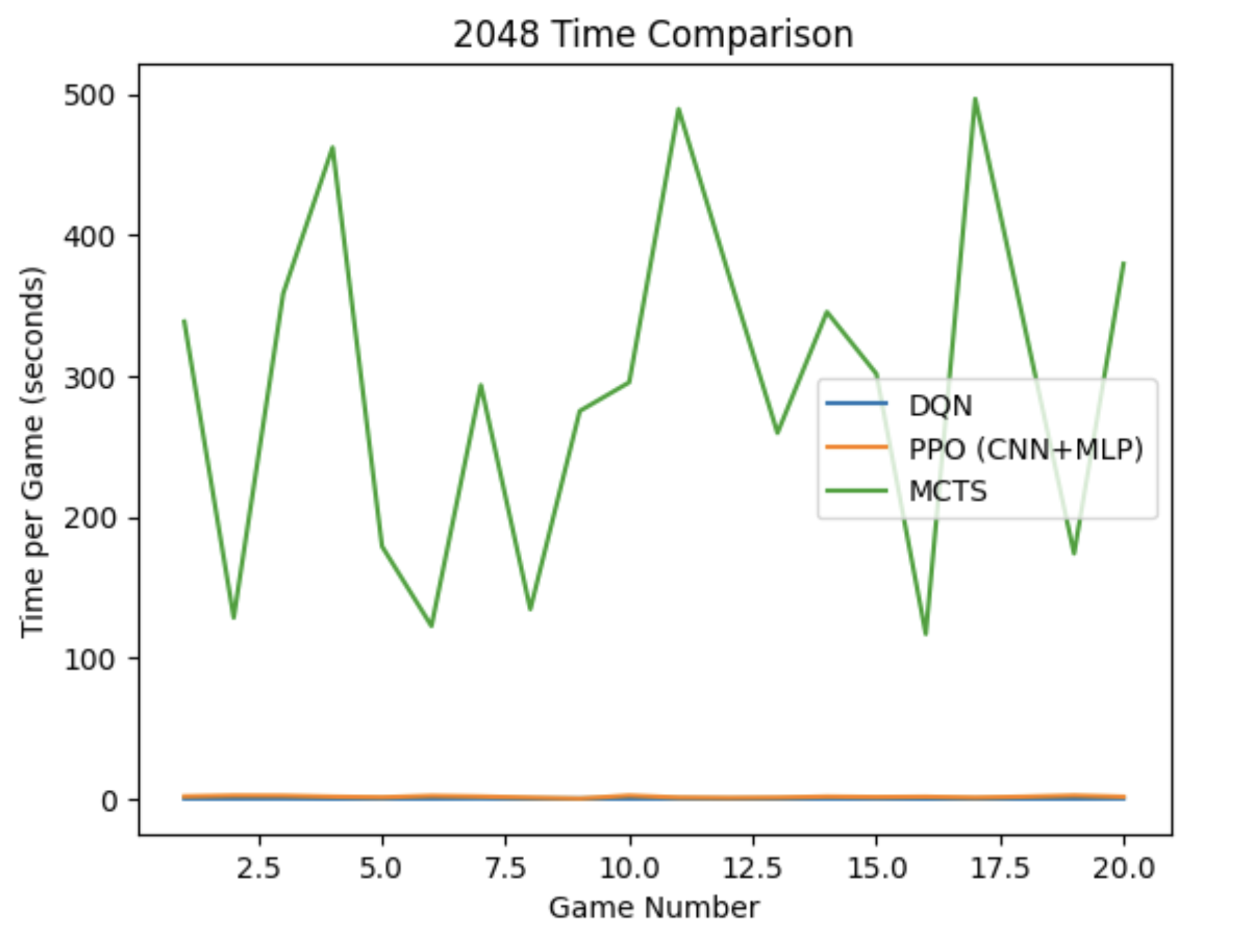
There is a clear direct correlation between max tile reached and total score across all three models. The main outlier is the time required per game — MCTS is the primary concern when comparing time vs. score, while PPO and DQN can be rapidly evaluated. This is inherent to MCTS's architecture of performing n rollouts per move.
There is a clear tradeoff between time and score when comparing MCTS to PPO. While MCTS achieves higher 2048 rates with sufficient compute, PPO is more stable — its 1024 and 512 rates are higher than MCTS's across equivalent test runs. PPO's robust design choices and carefully tuned heuristics make it the strongest model overall: it reaches 2048 at a reasonable training cost (50k episodes) and evaluates in approximately 1.5 seconds per game.
With further research into DQN parameterization and longer training times, we believe there is more to be achieved. DQN's reward plateau currently prevents it from reaching higher tiles, but with more compute and stronger architecture choices (additional layers, larger batch sizes, more timesteps), it could close the gap. More broadly, we can explore imitation learning with additional data, or train existing models on modified 2048 variants — such as including 8 as a randomly spawning tile, using a larger board, or adding move timers — to encourage adaptability.
AI tooling was used in the following capacities: